İfade ettiğimiz her şey (sözlü veya yazılı olarak) büyük miktarda bilgi taşır. Seçtiğimiz konu, üslubumuz, kelime seçimlerimiz, her şey ondan çıkarılabilecek yorumlara bir tür bilgi ekliyor. Teorik olarak, bu bilgiyi kullanarak insan davranışını anlayabilir ve hatta tahmin edebiliriz.
Ancak bir sorun var: Bir kişi konuşma yaparken yüzlerce veya binlerce kelime üretebilir ve her cümlenin veya her kelimenin kendi karmaşıklığı vardır. Belirli bir coğrafyadaki yüzlerce, binlerce veya milyonlarca insanı veya ifadelerini ölçeklendirmek ve analiz etmek istiyorsanız, durum yönetilemez hal alır.
Konuşmalardan, makalelerden ve hatta tweet’lerden üretilen veriler, yapılandırılmamış verilere örnektir. Yapılandırılmamış veriler, ilişkisel veritabanlarının geleneksel satır ve sütun yapısına tam olarak uymaz ve gerçek dünyada bulunan verilerin büyük çoğunluğunu oluşturur. Bunlar dağınık ve manipüle etmesi zor verilerdir. Yine de makine öğrenimi gibi disiplinlerdeki gelişmeler sayesinde bu konuda büyük bir devrim yaşanıyor. Günümüzde artık önemli olan bir metni veya konuşmayı anahtar kelimelerine dayalı olarak yorumlamaya çalışmak değil, bu kelimelerin arkasındaki anlamı anlamaktır. Bu şekilde ironi gibi konuşma şekillerini tespit etmek ve hatta duygu analizi yapmak mümkündür.
Doğal dil işleme (NLP), bilgisayarların insan dilini anlamasına, yorumlamasına ve manipüle etmesine yardımcı olan bir yapay zeka dalıdır. NLP, insan iletişimi ve bilgisayar anlayışı arasındaki boşluğu doldurma arayışında bilgisayar bilimi ve hesaplamalı dilbilim de dahil olmak üzere birçok disiplinden yararlanmaktadır.

NLP, veri bilimi ve insan dili arasındaki etkileşime odaklanan ve birçok sektöre ölçeklenen bir disiplindir. Bugün NLP, verilere erişimdeki devasa iyileştirmeler ve diğerlerinin yanı sıra uygulayıcıların sağlık, medya, finans ve insan kaynakları gibi alanlarda anlamlı sonuçlar elde etmesine olanak tanıyan hesaplama gücündeki artış sayesinde patlama yaşıyor.
NLP; sohbet botları(chatbots), makale veya yazıların özeti, dil çeviri ve veriden görüş tanımlama gibi birçok akıllı uygulamada kritik bir rol oynamaktadır. NLP ön-işleme, varlık(entity) çıkarımı, kelime frekanslarının ölçümleri gibi aşamalar içerir.
Metin ön-işlemede gürültü giderme(noise removel), sözlük normalize edilmesi(lexicon normalization), nesne standart oluşumu(object standarization) teknikleri kullanılır.
- Gürültü giderme ile “ve, veya, ama” gibi bağlaçlar üzerinde işlemler yapılır.
- Sözlük normalize “yaptım, yapıyorum, yapacağım” gibi aynı kökten gelen kelimelerin normalize oluşumu üzerindeki islemleri içerir.
- Nesne standart oluşumu ise “rt → retweet, dm → direct message” gibi kısaltmalar üzerinde yapılabilecek ön işleme teknikleridir.
Ön işlemeden sonra entity extraction (varlık çıkarma) özne yüklem ve nesnelerin belirlenmesi bu aşamada yapılır. Bu aşamada metinden ilgili konunun çıkarılması yapılır. Kullanılan tekniklerden biri de Latent Dirichlet Allocation for Topic Modelling (LDA).
Konu çıkarımının dışında kelime frekansları, sayısı, yoğunluğu gibi özellikler çıkarılabilir. Kelimelerin text içerisinde kullanım istatistikleri deep neural networks ve recurrent neural network ile hesaplanabilmektedir. (Glove, Word2Vec kullanılan kütüphanelerden bazıları)
NLP Uygulamaları:
- Metin Sınıflandırma ve Kategorizasyon (Text Classification and Categorization)
- Adlandırılmış Varlık Tanıma (Named Entity Recognition (NER) )
- Konuşma Bölümü Etiketleme (Part-of-Speech Tagging)
- Anlamsal Ayrıştırma ve Soru Cevaplama (Semantic Parsing and Question Answering)
- Yorum Bulma (Paraphrase Detection)
- Dil Üretimi ve Çok Belgeli Özetleme (Language Generation and Multi-document Summarization)
- Dil Çeviri (Machine Translation)
- Ses Tanıma (Speech Recognition)
- Karakter Tanıma (Character Recognition)
- Yazım Denetimi (Spell Checking)
- Spam ile mücadele (Fighting Spam)
- Özetleme(Summarization)
- Soru Cevaplama (Question Answering)
- Bilginin çıkarılması(Information Extraction)
NLP size birçok görevde yardımcı olabilir ve uygulama alanları günlük olarak artıyor gibi görünüyor. Bazı örneklerden bahsedelim:
- IBM’deki bir araştırmacı, hakkınızda her şeyi öğrenerek kişiselleştirilmiş bir arama motoru gibi çalışan bir bilişsel asistan geliştirdi. Bu asistan size bir adı, şarkıyı veya ihtiyacınız olduğu anda hatırlayamadığınız herhangi bir şeyi hatırlamanıza yardımcı oluyor.
- Yahoo ve Google gibi şirketler, sunucularından akan e-postalardaki metinleri analiz ederek ve spam postayı gelen kutunuza girmeden önce durdurarak NLP ile e-postalarınızı filtreler ve sınıflandırır.
- Sahte haberlerin belirlenmesine yardımcı olmak için, MIT’deki NLP Grubu, bir kaynağın güvenilir olup olmadığını tespit ederek, bir kaynağın doğru mu yoksa politik olarak önyargılı olup olmadığını belirlemek için yeni bir sistem geliştirdi.
- Amazon’un Alexa ve Apple’ın Siri’si, sesli uyarılara yanıt vermek ve belirli bir mağazayı bulmak, bize hava durumu tahminini söylemek, ofise en iyi rotayı önermek veya evdeki ışıkları yakmak gibi her şeyi yapmak için NLP’yi kullanan akıllı sistemler NLP teknolojisini bir başka örnekleridir.
Doğal Dil İşleme’nin ne olduğunu öğrendik hadi şimdi bir uygulama yapalım.
Bu örnekte Twitter kullanıcılarının attıkları tweetleri içeren bir veri seti kullanacağız. Bu veri setinde atılan tweetler “male” ve ”female” olarak iki adet cinsiyet sınıfı içeriyor. Amacımız veri setini güzelce temizleyip makine öğrenmesi sınıflandırma algoritmamızın anlayabileceği hale getirip daha sonra sınıflandırıp, bunu yüzde kaç doğruluk payı ile yaptığımızı öğrenmek.
Veri seti ingilizce olduğu için veri setini temizlemek için kullanacağımız metotlar hep ingilizce diline ait gramer yapılarını içeriyor.
Öncelikle veri setimizi import edelim:
import pandas as pd
data = pd.read_csv(r"gender_classifier.csv",encoding = "latin1") # Veri setini import edelim
data = pd.concat([data.gender,data.description],axis=1) # Atılan tweetleri ve cinsiyet sınıfını bu veri setinden alıp birleştirelim
data.dropna(axis = 0,inplace = True) # Na olan tweetleri silelim
data.gender = [1 if each == "female" else 0 for each in data.gender] # Female = "1" - Male = "0"
data.gender.value_counts() # Kaç tane 0 kaç tane 1 olduğunu görelim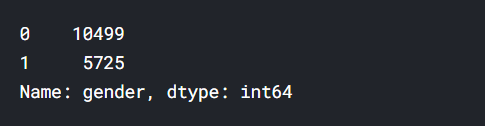
Şimdi veri setimizi temizlemeye başlayalım (Öncelikle temizleme işlemi tek bir tweet üzerinden yapılacaktır. Daha sonra basit bir for döngüsüyle yapılan bu işlemler bütün veri setine uygulanacaktır.)
Regular Expression:
Regular Expression, arama modeli oluşturan bir karakter dizisidir. Re kütüphanesi sayesinde, bir dizenin belirtilen arama modelini içerip içermediğini kontrol edebiliriz. Bizim bu kütüphaneyi kullanma amacımız tweetlerimizin içinde İngilizce harfler dışında (nokta, virgül veya parantez gibi) başka ifadeler var mı onu bulmak. Eğer var ise bunları boşluk ile değiştireceğiz.
import re
first_description = data.description[4]
print(first_description)
description = re.sub("[^a-zA-Z]"," ",first_description) # a dan z ye ve A dan Z ye kadar olan harfleri bulma geri kalanları " " (space) ile degistir
description = description.lower() # buyuk harftan kucuk harfe cevirme
print(description)

Tokenization:
Tokenization, bir metin parçasını token adı verilen daha küçük birimlere ayırmanın bir yoludur. Burada tokenler, kelimeler, karakterler veya alt kelimeler olabilir.

Stopwords (Gereksiz Kelimeler):
Stopwords, herhangi bir dildeki cümleye fazla anlam katmayan kelimelerdir. Cümlenin anlamından ödün vermeden güvenle göz ardı edilebilirler. İngilizce’de bu kelimelere “and”,”the”,”to” örnek verilebilir.
import nltk # natural language tool kit
nltk.download("stopwords") # Bu stopwordleri önce indirmemiz lazım
from nltk.corpus import stopwords # daha sonra kütüphaneyi import ediyoruz
description = nltk.word_tokenize(description) # tokenization
description = [ word for word in description if not word in set(stopwords.words("english"))] # Stopwordleri çıkarıyoruz
print(description)
Lemmatization (Kelimenin kökünü alma):
Basit olarak sözcüğün kökünü alma yöntemidir.
import nltk as nlp # Gerekli kütüphaneyi import ettiklemma = nlp.WordNetLemmatizer()description = [ lemma.lemmatize(word) for word in description] # kelimelerin köklerini aldıkdescription = " ".join(description) # ve bu kelimeleri tekrar liste halinden tek bir cümle haline getirdik
Haydi şimdi uyguladığımız bu yöntemleri bütün veri setine uygulayalım.
description_list = []
for description in data.description:
description = re.sub("[^a-zA-Z]"," ",description)
description = description.lower() # buyuk harftan kucuk harfe cevirme
description = nltk.word_tokenize(description)
#description = [ word for word in description if not word in set(stopwords.words("english"))]
lemma = nlp.WordNetLemmatizer()
description = [ lemma.lemmatize(word) for word in description]
description = " ".join(description)
description_list.append(description)Bag of Words:
Bir metin parçasındaki tüm kelimeleri saymanıza izin veren yaygın olarak kullanılan bir modeldir. Temel olarak, cümle veya belge için dilbilgisi ve kelime sırasını göz ardı ederek bir oluşum matrisi oluşturur. Bu kelime frekansları veya oluşumları daha sonra bir sınıflandırıcıyı eğitmek için değişken olarak kullanacağız.
from sklearn.feature_extraction.text import CountVectorizer # bag of words yaratmak icin kullandigim metotmax_features = 30count_vectorizer = CountVectorizer(max_features=max_features,stop_words = "english")sparce_matrix = count_vectorizer.fit_transform(description_list).toarray() # model eğitiminde input olarak kullanacağızprint("En sık kullanilan {} kelime = {}".format(max_features,count_vectorizer.get_feature_names())) # En sık kullanılan 30 kelimeyi yazdırıyoruz
Max_features ekrana çok fazla kelime yazdırmamak için 30 adet girildi fakat siz 5000–10000 arası girebilirsiniz. Bag of Word uyguladıktan sonra elimizde makine öğrenmesi sınıflandırma algoritmasında kullanacağımız bir matris var. Bu bizim input değişkenimiz olucak. Daha önce 1 ve 0 olarak ayrıdığımız cinsiyet sınıdı bizim output değişkenimiz olucak.
Makine Öğrenmesi Modeli:
Verimizi güzelce temizledik ve makine öğrenmesi sınıflandırma algoritmasında kullanılabilecek hale getirdik. Sınıflandırma algoritması olarak Naive Bayes Algoritması kullanıldı.
y = data.iloc[:,0].values # Output değişkeni
x = sparce_matrix # input değişkeni
# train test split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size = 0.1, random_state = 42)
# Naive bayes
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB()
nb.fit(x_train,y_train)
# Prediction
y_pred = nb.predict(x_test)
print("accuracy: ",nb.score(y_pred.reshape(-1,1),y_test))
Son olarak cinsiyet sınıflandırma accuracy değerimizi de bulduk. Bu değer normal şartlar altında çok düşük bir değer. Zaten iki tane farklı output değerimiz var. Rastgele bir seçim yapsak bile %50 şansımız var. Fakat, buradaki amacımız doğal dil işlemenin nasıl uygulandığını öğrenmek. Sizler daha farklı sınıflandırma algoritmaları kullanarak daha iyi accuracy değerleri bulabilirsiniz.
