In the evolving landscape of machine learning, one of the most challenging obstacles is the scarcity of labeled data in supervised learning scenarios. This limitation can significantly hinder the development and accuracy of predictive models. However, various strategies and techniques can be employed to overcome this hurdle, maximizing the value of available data. This article, drawing upon insights from Sebastian Raschka, explores these methods, offering a guide for practitioners and enthusiasts alike in the field of machine learning.

Labeling More Data
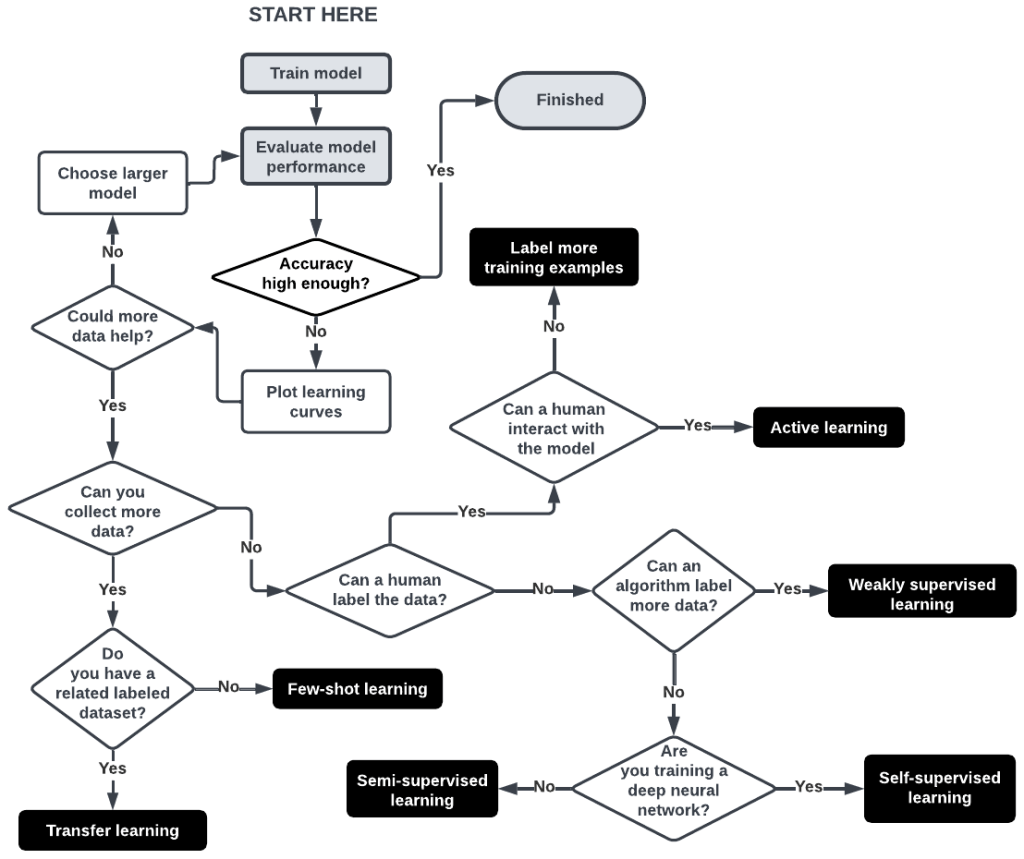
At the heart of supervised learning lies the need for labeled data. The more data a model can learn from, the better its performance typically is. However, collecting additional data is not always practical due to constraints like cost, time, or accessibility. This brings us to alternative approaches, which are crucial when expanding the dataset is not feasible. These alternatives do not replace the need for more data but offer ways to maximize the utility of existing datasets.
Bootstrapping the Data
Bootstrapping the data is a method that involves generating additional training examples either by modifying existing data (data augmentation) or creating artificial ones (synthetic data). This approach can significantly enhance the model’s ability to learn and generalize from a limited dataset. For instance, in image recognition tasks, simple transformations like rotating or flipping images can effectively increase the dataset’s size. Similarly, in text-based applications, techniques like synonym replacement can create varied linguistic examples. Improving data quality, alongside quantity, can also yield substantial improvements in model performance.
Transfer Learning
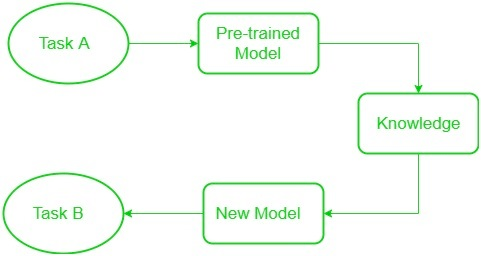
Transfer learning has emerged as a powerful tool in the realm of deep learning. It involves training a model on a large, general dataset (like ImageNet) and then fine-tuning it on a more specific target dataset. This method leverages the knowledge gained from a broader context, applying it to a more narrowly focused task. This is particularly effective in scenarios where labeled data is limited. In contrast to methods like decision tree algorithms, which are nonparametric and lack iterative training capabilities, deep learning models benefit from their ability to update model weights, making transfer learning a preferred approach in many deep learning applications.
Self-supervised Learning
Self-supervised learning represents a significant shift in approach compared to traditional machine learning methods. This technique involves pretraining a model on a task for which data is abundant, often using label information that can be automatically extracted from the data itself. This pretraining step is followed by fine-tuning the model on the target task, where labeled data is scarce. For example, in language models like GPT or BERT, tasks such as predicting the next word or filling in a missing word help the model learn language patterns before it’s applied to more specific tasks. This method effectively utilizes vast amounts of unlabeled data, a common scenario in many real-world applications.
Active Learning
Active learning is a dynamic approach that involves human participation in the labeling process. Unlike traditional methods where a model is trained on a pre-labeled dataset, active learning selects the most informative data points for labeling. This prioritization is based on the model’s current understanding and aims to choose examples that would most improve its performance. This approach is especially useful when labeling is expensive or time-consuming, as it ensures that the effort is concentrated on the most valuable data. By iteratively updating the model with new labels, active learning can achieve high performance with fewer labeled examples.
Few-shot Learning
Few-shot learning tackles the challenge of learning from extremely limited data — often just a few examples per class. This approach is prevalent in research contexts, with scenarios like 1-shot learning (one example per class) and 5-shot learning (five examples per class) being common. Few-shot learning relies on techniques that allow a model to make significant generalizations from minimal data. This can involve sophisticated algorithms that focus on understanding the underlying patterns and relationships in the data, rather than merely memorizing specific examples.
Meta-learning
Meta-learning, or “learning to learn,” is a fascinating area of machine learning that focuses on developing methods to improve how algorithms learn from data. There are several approaches to meta-learning, each with its unique focus. One key area in meta-learning is related to few-shot learning, where the emphasis is on learning effective feature extraction methods that can be applied to new tasks with minimal data. Another distinct branch of meta-learning involves analyzing meta-data (meta-features) from datasets to better understand and improve the learning process for supervised tasks. This multifaceted approach allows for the development of more adaptable and efficient learning algorithms.
Weakly Supervised Learning
Weakly supervised learning is a strategy where external, often less accurate or noisier sources, are used to generate labels for a dataset. This approach is particularly useful when high-quality labels are unavailable or too costly to obtain. The labels generated through weak supervision may not be as precise as those from domain experts, but they can provide a valuable starting point for training models. Techniques like label propagation and the use of heuristic rules are common in weakly supervised learning, allowing the model to leverage broader, albeit less precise, information sources to learn patterns in the data.
Semi-supervised Learning
Semi-supervised learning sits at the intersection of supervised and unsupervised learning. In this approach, a combination of a small amount of labeled data and a large amount of unlabeled data is used. The primary difference from weakly supervised learning is the method of label generation. Semi-supervised learning often relies on the inherent structure of the data, using techniques like clustering or graph-based methods to infer labels for the unlabeled data. This method is particularly powerful when the unlabeled data can provide significant insights into the overall data distribution, aiding in more accurate model training.

Self-training
Self-training, a blend of semi-supervised and weakly supervised learning, involves using a model, often referred to as a pseudo-labeler, to annotate a dataset. Initially, the model is trained on a small set of labeled data. Then, it’s used to predict labels for the unlabeled data. These predicted labels, despite potentially being less accurate, are used to retrain the model, creating a feedback loop that can progressively improve the model’s performance. This approach is especially useful in scenarios where obtaining a large labeled dataset is impractical, allowing the model to bootstrap its way to better performance using its own predictions.
Multi-task Learning
Multi-task learning is an approach where a single model is trained on multiple related tasks simultaneously. This technique leverages the commonalities and differences across tasks to improve the model’s generalization capabilities. For example, in natural language processing, a model might be trained on both sentiment analysis and topic classification. The underlying idea is that learning related tasks together allows the model to share representations and insights across tasks, leading to more robust and versatile models. Multi-task learning is particularly effective when the tasks are complementary, enabling the model to build a more comprehensive understanding of the data.
Multi-modal Learning
Multi-modal learning is a sophisticated approach in machine learning that integrates various types of data inputs, or “modalities,” to improve the learning process. Unlike multi-task learning, which focuses on multiple tasks, multi-modal learning involves the incorporation of different forms of data, such as text, images, and audio, into a single model. This integration allows the model to capture a richer and more comprehensive understanding of the data. For instance, in a sentiment analysis task, a multi-modal system might analyze both the text of a product review and the sentiment expressed in the accompanying image. By combining information from different sources, multi-modal learning can provide more nuanced insights and predictions, especially beneficial in contexts where single-mode data is limited or insufficient for comprehensive analysis.
Inductive Biases
Inductive biases refer to the assumptions a machine learning model makes about the data it is learning from. These biases are inherent in the design of the model and can greatly influence its performance, especially in situations with limited data. For example, convolutional neural networks (CNNs) assume that nearby pixels in an image are more related than distant ones, making them particularly effective for image-related tasks. By choosing models with appropriate inductive biases for the task at hand, it’s possible to reduce the amount of data required for effective training. This approach relies on leveraging the underlying structure and nature of the data, allowing the model to make more informed guesses about unseen instances.
Choosing the Right Techniques
With a plethora of techniques available for dealing with limited labeled data, choosing the most suitable one depends on the specific circumstances of the task. Factors such as the amount and type of data available, the nature of the task, the desired accuracy, and the available computational resources all play a crucial role in this decision. It’s often beneficial to experiment with multiple techniques or combine them to achieve the best results. Understanding the strengths and limitations of each method is key to making informed decisions and effectively addressing the challenges posed by limited labeled data.
Conclusion
The challenge of limited labeled data in machine learning is significant, but as we have seen, there are many innovative approaches to tackle this issue. From enhancing existing data through bootstrapping and transfer learning to leveraging the structure of data in semi-supervised and multi-task learning, each technique offers unique advantages. As machine learning continues to evolve, the ability to effectively learn from limited data will become increasingly important, opening new frontiers in AI research and application. Practitioners are encouraged to explore these techniques and apply them creatively to their specific challenges.
Acknowledgments
This comprehensive exploration of strategies for mastering machine learning with minimal data draws upon the expertise and insights of Sebastian Raschka.
Source: https://sebastianraschka.com
