1. Introduction
In the landscape of deep learning, models are typically designed to predict a target variable given an input . Autoencoders, however, subvert this paradigm. At their core, an autoencoder is a neural network trained to reproduce its own input, effectively learning to approximate the identity function .
While training a network to act as a simple “copy machine” might sound mathematically trivial, the true power of an autoencoder lies in its architectural constraints. By forcing the input data through a low-dimensional bottleneck before reconstructing it, the network is restricted from simply memorizing the input space. Instead, it is compelled to learn a compact, informative representation of the data’s underlying continuous manifold. This compressed latent representation serves as a powerful foundation for a multitude of advanced downstream tasks.
1.1. The Autoencoder Concept
Autoencoders belong to the broader family of self-supervised learning architectures. In these systems, the supervision signal is derived inherently from the data itself rather than from expensive, human-annotated labels. The network learns to predict missing or transformed parts of the data from the remaining parts.
In the specific case of an autoencoder, the “missing part” is the entirety of the original input. By minimizing the reconstruction error between the input data and the output prediction, the network naturally learns to encode the most salient features necessary for faithful reconstruction, discarding noise and redundant information in the process.
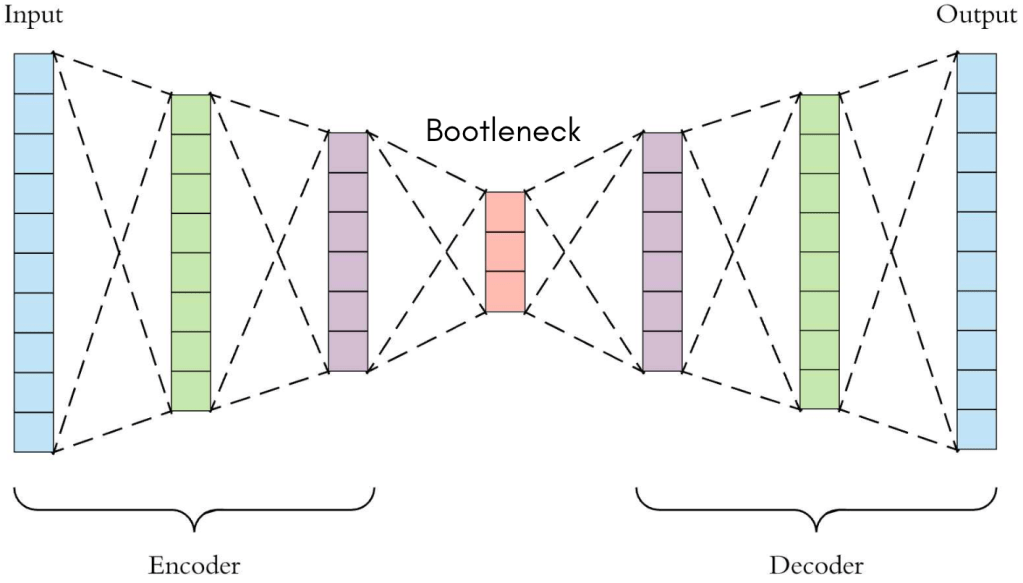
Figure 1 – High-level conceptual diagram of an autoencoder, illustrating the input mapping to a compressed latent code and expanding back to the reconstructed output [1].
1.2. Primary Objectives
The motivation behind deploying autoencoders generally falls into three primary objectives:
- Dimensionality Reduction and Manifold Learning: Similar to classical linear techniques like Principal Component Analysis (PCA), autoencoders learn a compressed representation that captures the intrinsic variance of a dataset in far fewer dimensions. However, because neural networks utilize non-linear activation functions, autoencoders can successfully model complex, non-linear data manifolds that linear hyperplanes cannot capture.
- Denoising and Robust Representation: By intentionally corrupting input data (e.g., adding Gaussian noise) and training the network to reconstruct the original, uncorrupted signal, we create a Denoising Autoencoder. This forces the model to learn features that are invariant to small perturbations, effectively projecting noisy data back onto the true data manifold—an essential property for robust perception and sensor pipelines.
- Feature Extraction for Downstream Tasks: The latent space—the narrowest point of the network—acts as a repository of highly abstracted features. Once an autoencoder is trained, the encoder half can be detached and used as an unsupervised feature extractor. These rich, low-dimensional embeddings can drastically improve the performance and convergence speed of subsequent classification, clustering, or visualization tasks.
1.3. Article Structure
Beyond basic reconstruction, the autoencoder framework serves as a conceptual bridge between traditional representation learning and modern generative modeling. This article will deconstruct the architecture, implementation, and evolution of autoencoders. The progression is organized as follows:
- Section 2 formalizes the core architecture and mathematical foundations, detailing the precise mappings of the encoder, the geometry of the latent space, and the probabilistic interpretation of reconstruction loss functions.
- Section 3 examines the MLP Autoencoder, illustrating how fully connected layers handle unstructured data, accompanied by a foundational PyTorch implementation.
- Section 4 extends these principles to image data via the CNN Autoencoder, highlighting the necessity of spatial coherence and convolutional downsampling.
- Section 5 bridges theory and practice by exploring real-world applications, with a deep dive into using reconstruction error for unsupervised anomaly detection.
- Section 6 introduces the generative extension: the Variational Autoencoder (VAE). We will explore how injecting probabilistic inference and the reparameterization trick into the latent space laid the groundwork for today’s advanced generative AI models.
2. Core Architecture and Mathematical Foundations
At the heart of every autoencoder lies a simple but powerful premise: a neural network can learn to compress information and subsequently reconstruct it. This is achieved through a tripartite architecture composed of an encoder, a latent space (or bottleneck), and a decoder. Each component plays a distinct functional role in transforming high-dimensional input data into a lower-dimensional manifold and then projecting it back to the original input space.
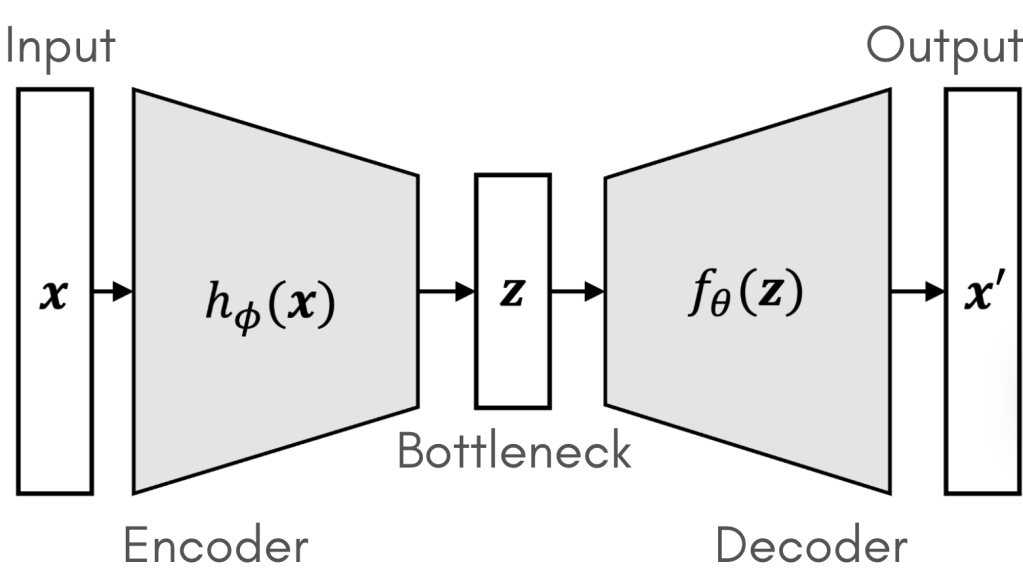
Figure 2 – Detailed schematic of encoder, bottleneck, decoder, and loss feedback [2].
2.1. The Encoder Mapping
The encoder is a deterministic mapping function, typically parameterized by a neural network, that compresses the input vector into a latent representation.
Let the input data be denoted as . The encoder function , parameterized by weights and biases , maps the input to a latent vector :
For a standard feedforward layer, this operation can be expanded as , where is the weight matrix, is the bias vector, and is a non-linear activation function (such as ReLU or GeLU). The encoder’s objective is to capture the most salient, invariant features of the data distribution while systematically discarding noise and redundancy.
2.2. The Latent Space (Bottleneck)
The latent space, often referred to as the bottleneck, is the compressed internal representation carrying the structural essence of the input. Its dimensionality, , dictates the information capacity of the network.
Geometrically, the latent space can be interpreted as a low-dimensional manifold embedded within the high-dimensional input space . By forcing the network to route all information through this restrictive bottleneck , we prevent it from trivially memorizing the data. Instead, the network must learn the intrinsic coordinates of this manifold, ensuring that each point corresponds to a distinct, structurally valid reconstruction.
2.3. The Decoder Mapping
The decoder performs the inverse geometric transformation, projecting the low-dimensional latent codes back into the original, high-dimensional input space.
Denoted as and parameterized by , the decoder maps the latent vector to a reconstructed output :
Together, the encoder and decoder form a composite function. The network’s success is determined by how closely the reconstruction mirrors the original input .
2.4. Reconstruction Loss Functions: A Probabilistic Perspective
Training an autoencoder involves minimizing a reconstruction loss . While standard implementations treat this as a simple error metric, it is fundamentally grounded in Maximum Likelihood Estimation (MLE). The choice of loss function implies a specific probabilistic assumption about the underlying data distribution.
- Mean Squared Error (MSE) and the Gaussian Assumption: MSE is the default choice for continuous data. Minimizing the MSE is mathematically equivalent to maximizing the log-likelihood of the data, assuming the decoder’s output defines the mean of a multivariate isotropic Gaussian distribution with fixed variance.
- Binary Cross-Entropy (BCE) and the Bernoulli Assumption:If the input features are binary or normalized to the [0, 1] interval (e.g., pixel intensities), BCE is the mathematically correct objective. BCE assumes the targets are drawn from a multivariate Bernoulli distribution, treating the decoder’s output as the parameter (probability) of that distribution.
2.5. Undercomplete vs. Overcomplete Networks
Autoencoders are categorized by the relationship between the input dimension and the latent dimension :
- Undercomplete Autoencoders (): This is the standard configuration. The strict bottleneck naturally forces dimensionality reduction and feature extraction without requiring explicit regularization.
- Overcomplete Autoencoders (): When the latent space is larger than or equal to the input space, the network possesses enough capacity to learn a trivial identity mapping () without extracting meaningful features. To prevent this, overcomplete models require strict mathematical constraints:
- Sparse Autoencoders: Introduce a sparsity penalty (e.g., an L1 regularization term or a Kullback-Leibler divergence penalty) on the latent activations. This forces the model to represent inputs using only a small, specialized subset of active neurons, learning highly localized features.
- Contractive Autoencoders: Penalize the sensitivity of the latent representation to small variations in the input. This is achieved by adding the Frobenius norm of the encoder’s Jacobian matrix to the loss function: . This explicitly forces the manifold to be robust against local perturbations.
2.6. Training Procedure
Despite being an unsupervised algorithm, an autoencoder is trained using the standard supervised learning machinery—the only difference is that the input acts as its own target label.
The optimization loop proceeds as follows:
- Forward Pass: Compute the latent representation and the reconstruction
- Loss Calculation: Evaluate the objective function , augmented with any regularization terms (e.g., sparsity or contractive penalties).
- Backward Pass: Backpropagate the error gradients through the decoder and then through the encoder using the chain rule.
- Parameter Update: Adjust the weights and using gradient-based optimizers such as Adam or Stochastic Gradient Descent (SGD).
Each layer is followed by a non-linear activation function, such as ReLU, to introduce expressive capacity. The final decoder layer typically uses a Sigmoid activation when input data are normalized to the [0, 1] range.
Finding the right latent size is therefore a balance between compression efficiency and reconstruction quality. This trade-off is typically explored empirically through experiments on validation data.
3. The Multilayer Perceptron (MLP) Autoencoder
The Multilayer Perceptron (MLP) autoencoder is the most fundamental instantiation of the autoencoder family. Built exclusively from fully connected (dense) layers, this architecture treats input data as flat, one-dimensional vectors. While it is the standard choice for tabular datasets, sensor arrays, or low-dimensional continuous signals, examining its application to image data reveals both the core principles of representation learning and the inherent limitations of feedforward networks.
3.1. Architectural Overview
An MLP autoencoder dictates that every neuron in a given layer is connected to every neuron in the subsequent layer. The architecture symmetrically scales down the input into the latent space and then scales it back up.
Consider a standard baseline task: reconstructing grayscale images from the MNIST dataset. An original pixel image is first flattened into a vector . The network architecture sequentially compresses this vector:
- Encoder Pathway:
- Latent Space (): A 32-dimensional bottleneck.
- Decoder Pathway:
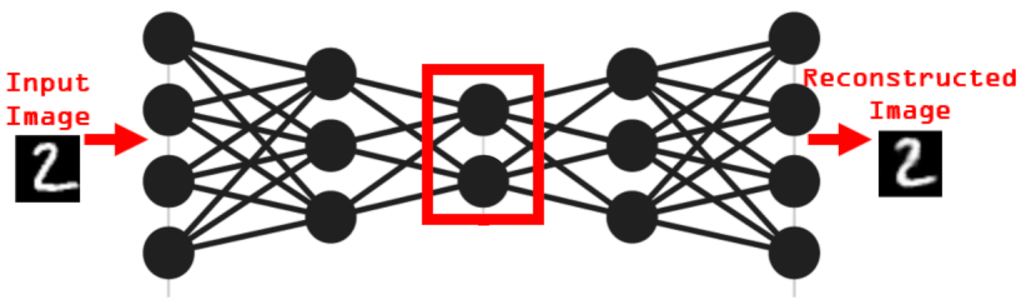
Figure 3: Example structure of an MLP autoencoder and sample reconstructions for the MNIST dataset. The left column shows input digits; the right column shows reconstructed outputs [3]
Each intermediate layer applies a non-linear activation function, such as ReLU (), to learn complex, non-linear mappings. The final layer of the decoder typically applies a Sigmoid activation () to constrain the reconstructed pixel values strictly within the range, matching the normalized input distribution.
3.2. Bottleneck Sizing: The Compression Trade-off
The dimensionality of the latent space is the most critical hyperparameter in an MLP autoencoder. It governs a strict trade-off between compression efficiency and reconstruction fidelity:
- Aggressive Compression (Small d): Enforces a tight informational bottleneck. The network is forced to learn only the most dominant eigenvectors (or their non-linear equivalents) of the data distribution. While excellent for anomaly detection and noise reduction, overly aggressive compression results in severe underfitting, leading to highly blurred or generalized reconstructions.
- Loose Compression (Large d): Preserves more variance from the input. While this minimizes the reconstruction loss (), it increases the risk that the network will learn redundant features or default to a trivial identity mapping, effectively memorizing the training set without extracting generalizable structural rules.
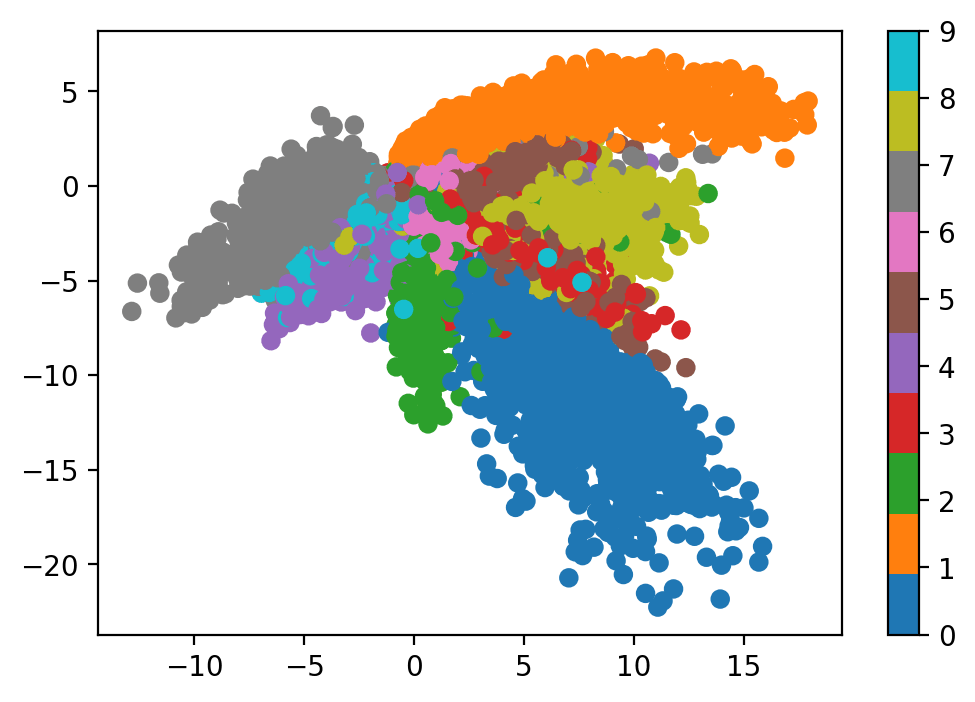
Figure 4 – Latent space visualization. By projecting the 32-dimensional latent vectors down to 2D using t-SNE or UMAP, we can observe how the autoencoder naturally clusters similar structural inputs, such as digits of the same class, without any label supervision.
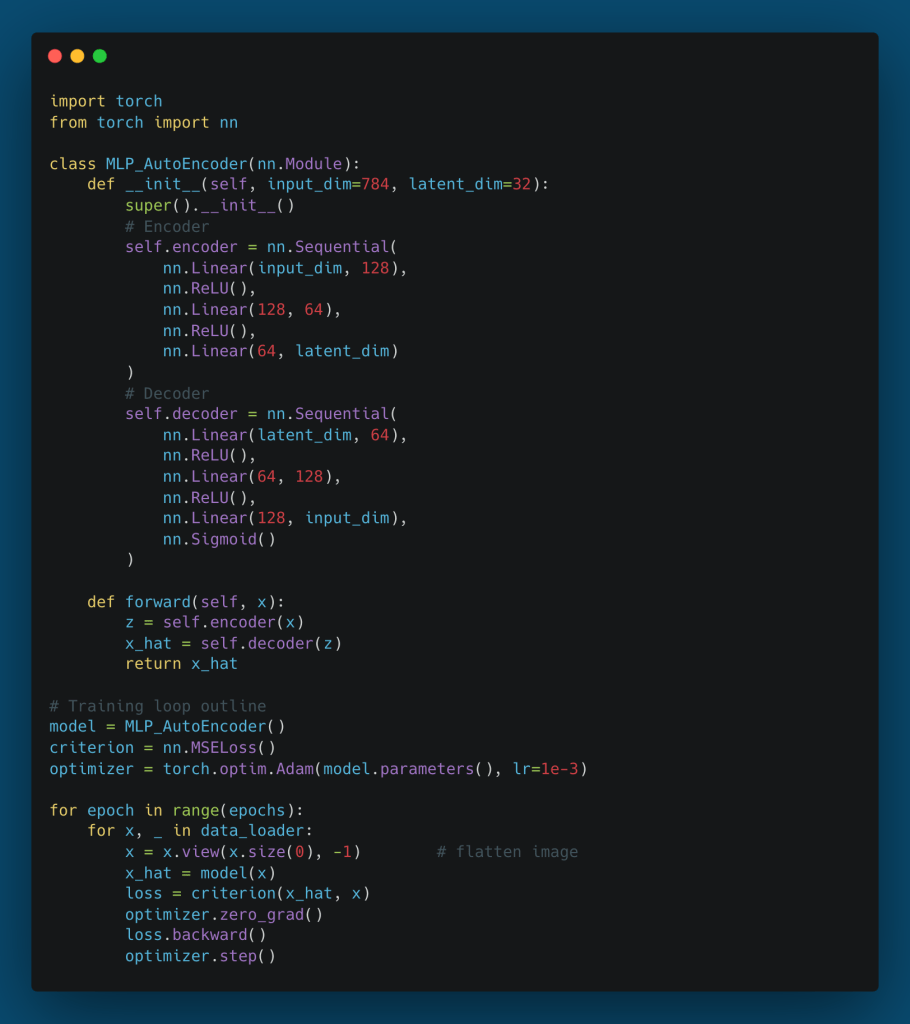
3.3. PyTorch Implementation
The following code provides a robust, minimal implementation of an MLP autoencoder in PyTorch using nn.Sequential blocks. This structure emphasizes the symmetry between the encoder and decoder.
3.4. Reconstruction Quality and Spatial Limitations
When trained on visually simple datasets like MNIST, the MLP autoencoder successfully learns to reconstruct the inputs. However, a critical analysis of the outputs reveals a distinct blurriness and occasional structural tearing.
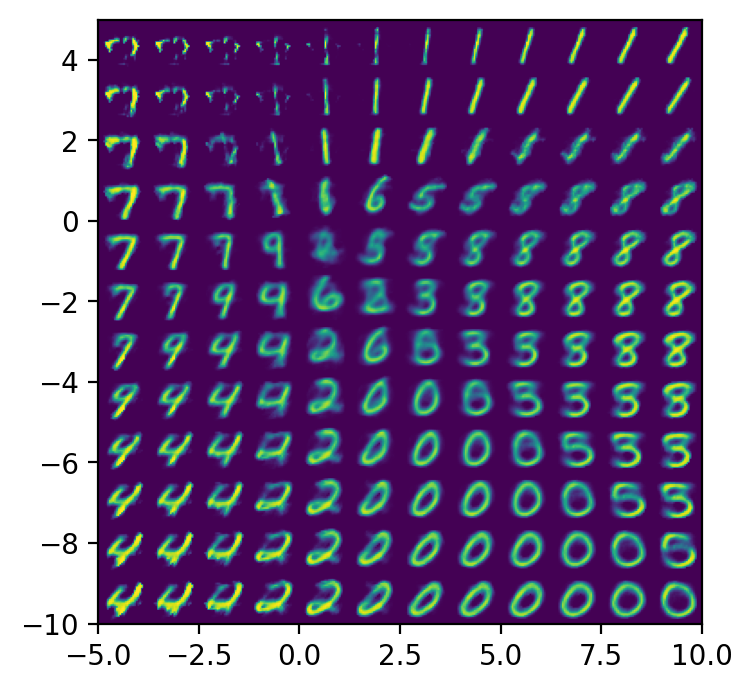
Figure 5 – MNIST reconstruction samples from latent space
This degradation is not merely a failure of capacity, but a fundamental architectural flaw when dealing with high-dimensional spatial data:
- Loss of Spatial Locality: By flattening a 2D image into a 1D vector, the MLP destroys the local grid structure. It treats two adjacent pixels with the exact same mathematical independence as two pixels on opposite corners of the image.
- Lack of Translation Invariance: If a feature (like a curved edge) appears in the top-left of an image during training, an MLP must learn a completely separate set of weights to recognize that exact same edge if it appears in the bottom-right.
- Parameter Inefficiency: Fully connected layers require a massive number of parameters. Scaling an MLP to handle high-resolution images (e.g., ) becomes computationally intractable and highly prone to overfitting.
To effectively reconstruct and generate high-fidelity spatial data, the architecture must natively respect local correlations—a requirement that leads us directly to the Convolutional Autoencoder.
4. The Convolutional Neural Network (CNN) Autoencoder
As established in the previous section, treating high-dimensional spatial data (like images) as flattened one-dimensional vectors strips away critical structural context. The Multilayer Perceptron is fundamentally agnostic to spatial locality. To build an autoencoder capable of capturing the rich, hierarchical structure of visual data, we must embed a strong inductive bias into the architecture. The Convolutional Neural Network (CNN) Autoencoder achieves this by leveraging local receptive fields, shared weights, and spatial pooling.
4.1. Spatial Coherence and the Convolutional Inductive Bias
Natural images contain profound local correlations; adjacent pixels are highly likely to share similar properties and belong to the same structural features (e.g., edges, textures). A CNN autoencoder respects this spatial coherence through the convolution operation.
Instead of learning a unique, dense weight for every pixel combination, a convolutional encoder sweeps learned filters (kernels) across the input. This provides two critical theoretical advantages:
- Parameter Efficiency: The weights of a kernel are shared across the entire spatial domain, drastically reducing the parameter count and mitigating the risk of overfitting on high-resolution data.
- Translation Invariance: A feature learned in one region of the image can be seamlessly recognized in another. If the encoder learns a Gabor-like filter to detect a vertical edge in the top-left corner, that exact same filter will successfully encode a vertical edge in the bottom-right.
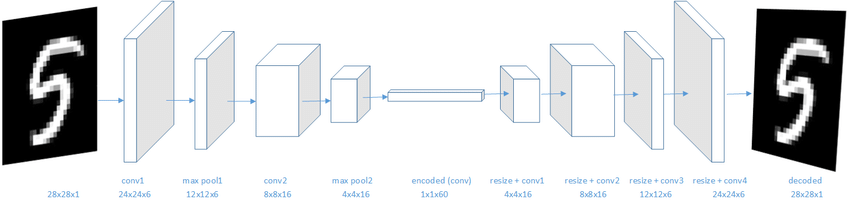
Figure 6 – CNN autoencoder architecture showing spatial down-sampling through convolutions and up-sampling through transposed convolutions, converging at a dense bottleneck [4].
4.2. Downsampling and Upsampling Mechanics
A CNN autoencoder replaces dense compression with a geometric reduction of spatial dimensions accompanied by an expansion in channel depth.
- The Convolutional Encoder (Downsampling): As the input tensor passes through successive convolutional layers, we typically apply a stride of (or use pooling layers, though strided convolutions are generally preferred in modern architectures to allow the network to learn its own spatial downsampling). For a spatial dimension of , a convolutional layer with a kernel size , padding , and stride reduces the output dimension to: . This process increases the receptive field of the deeper neurons, allowing the network to encode highly abstract, global features into the latent space while squashing the spatial grid.
- The Convolutional Decoder (Upsampling): To reconstruct the original input, the decoder must invert this spatial compression. This is mathematically achieved using Transposed Convolutions (sometimes inaccurately referred to as “deconvolutions”). A transposed convolution broadcasts an input activation across a spatial neighborhood weighted by the kernel, effectively expanding the feature map. Careful selection of the
output_paddingparameter is often required to resolve dimensional ambiguities that arise during strided downsampling, ensuring the reconstructed tensor perfectly matches the original image resolution.
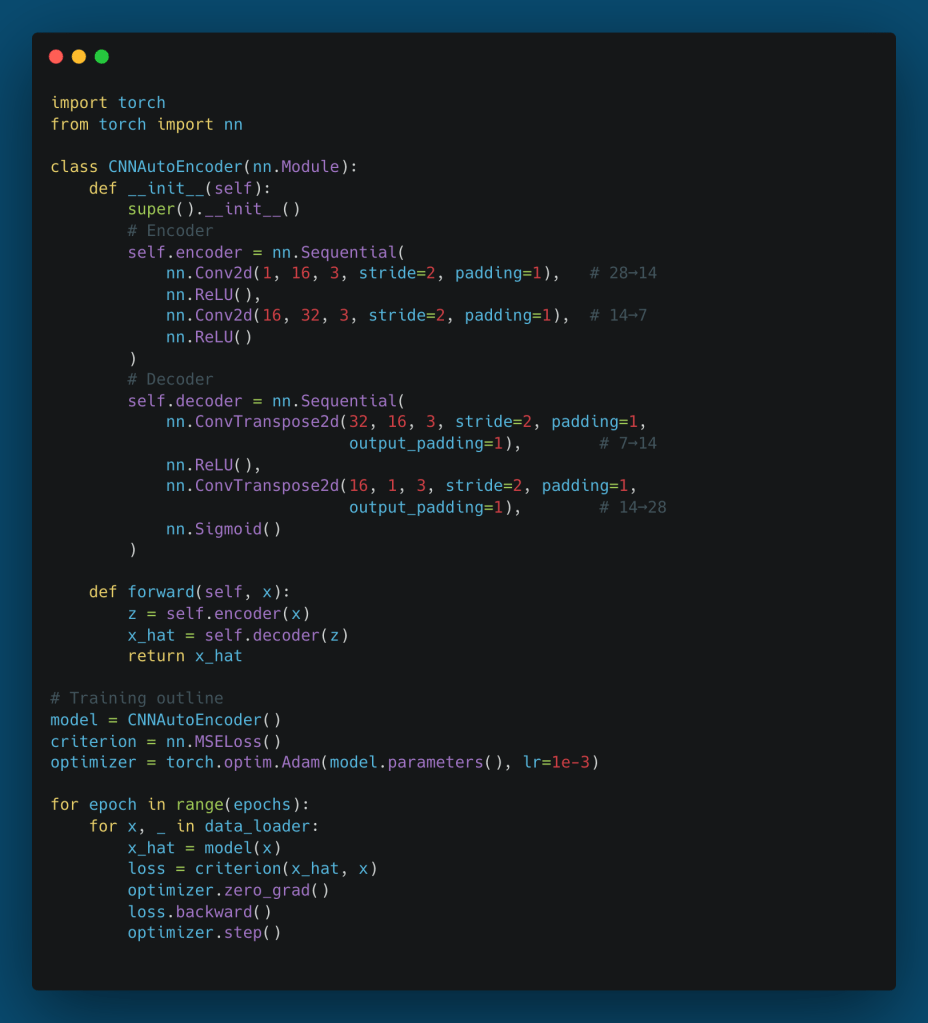
4.3. PyTorch Implementation
The following implementation demonstrates a robust CNN autoencoder designed for single-channel images like MNIST. Notice how the encoder transforms the spatial tensor into a true vector bottleneck to force holistic representation learning, before reshaping it for the spatial decoder.
4.4. Comparative Analysis: MLP vs. CNN Autoencoders
When comparing the empirical results of CNN autoencoders against their MLP counterparts on visual data, the theoretical advantages of convolutional architectures translate into stark performance differences:
| Aspect | MLP Autoencoder | CNN Autoencoder |
| Input Format | Flattened vectors (1D) | Spatial tensors (2D/3D) |
| Spatial Awareness | None (destroys grid context) | Preserved (exploits local correlation) |
| Parameter Efficiency | Extremely low; scales quadratically | High; scales by kernel size and depth |
| Feature Hierarchy | Global, unstructured | Local Global (edges to objects) |
| Reconstruction Quality | Blurry, lacking fine structural details | Sharp, preserving edges and textures |
The CNN autoencoder thus forms the essential bridge between simple reconstructive networks and modern, high-fidelity computer vision systems. By successfully mapping high-dimensional spatial data into reliable, dense latent codes, these networks unlock powerful downstream applications. In the next section, we will explore how this reconstructive capacity is practically deployed to solve unsupervised problems, most notably in the domain of anomaly detection.
5. Practical Applications: Anomaly Detection and Beyond
While autoencoders are fundamentally designed for representation learning, their unique ability to learn the intrinsic structure of a dataset without labels makes them incredibly powerful for applied machine learning. One of the most ubiquitous and commercially valuable applications of this architecture is unsupervised anomaly detection. By leveraging the reconstruction error as a measurable proxy for “normality,” we can identify out-of-distribution events in complex, high-dimensional spaces where traditional rule-based logic fails.
5.1. The Principle of Anomaly Detection
The mathematical intuition behind autoencoder-based anomaly detection relies on the geometry of the latent space.
During the training phase, the autoencoder is exposed exclusively to “normal” or baseline data. Consequently, the encoder learns to map only the manifold of this normal distribution, and the decoder learns to project from this specific subspace back to the original dimensions. The network allocates its limited parameter capacity entirely to minimizing the reconstruction loss of typical structural patterns.
During inference, when the network encounters an anomalous input (e.g., a defective part, a fraudulent transaction, or a network intrusion), the encoder is forced to project this unseen pattern onto the nearest point of the “normal” latent manifold. Because the anomaly lacks the structural correlations the network was optimized for, the decoder will reconstruct it poorly, yielding a high reconstruction error.
The anomaly detection pipeline is formalized as follows:
- Compute Reconstruction Error: For a new sample compute .
- Establish a Threshold: Define a scalar threshold . This is typically derived statistically from the validation set of normal data (e.g., the 95th or 99th percentile of baseline reconstruction errors).
- Classification: If , flag the sample as anomalous.
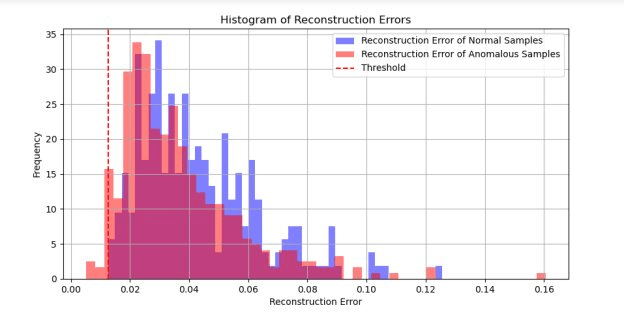
Figure 8 – Anomaly detection thresholding concept. A histogram showing the distribution of reconstruction errors for normal data versus anomalous data, illustrating the separability provided by the threshold [5].
5.2. Cross-Domain Applications
This reconstructive approach to outlier detection is highly adaptable and has been deployed across numerous technical domains:
- Industrial Robotics and Predictive Maintenance: Modern robotic arms and CNC machines generate continuous streams of multivariate sensor data (e.g., joint torques, vibrations, acoustic emissions). By training an MLP or 1D-CNN autoencoder on data from healthy operational cycles, engineers can monitor the real-time reconstruction loss. A gradual upward trend in often indicates mechanical wear or impending bearing failure long before it causes a catastrophic shutdown.
- Automated Visual Inspection: In semiconductor manufacturing or textile production, labeling every possible defect type (scratches, misalignments, impurities) is impossible. A CNN autoencoder trained solely on flawless components will fail to reconstruct a scratch on a silicon wafer. By examining the pixel-wise difference between the input image and the reconstruction (), the system can instantly generate a heatmap localizing the exact position of the defect.
- Cybersecurity and Intrusion Detection: Network traffic patterns can be encoded into feature vectors (e.g., packet sizes, sequence timing, protocol types). Sequence-based autoencoders (using 1D Convolutions or LSTMs) trained on routine network traffic will output massive reconstruction spikes when encountering the novel payload structures or timing anomalies characteristic of zero-day exploits or DDoS attacks.
5.3. Expanding Utility: Denoising and Pretraining
Beyond anomaly detection, the autoencoder framework serves as a versatile utility belt for data scientists:
- Denoising Autoencoders (DAE): DAE intentionally corrupts the input data with stochastic noise (e.g., or random dropout) but calculates the loss against the clean original target. This severs the identity mapping entirely, forcing the network to learn robust, invariant features that capture the true data-generating distribution rather than local noise.
- Dimensionality Reduction: The bottleneck layer provides a powerful non-linear alternative to PCA. Extracting the latent vectors yields dense, informative embeddings that can be fed into traditional clustering algorithms (like DBSCAN) or projected into 2D/3D spaces using algorithms like t-SNE and UMAP for data visualization.
- Unsupervised Pretraining: In domains where unlabeled data is abundant but labeled data is scarce (e.g., medical imaging), an autoencoder can be trained on the massive unlabeled corpus. The decoder is then discarded, and the pre-trained encoder weights are transferred to initialize a supervised classification network. This provides a massive head start on feature extraction, leading to faster convergence and higher accuracy on the limited labeled dataset.
Figure 9 – Examples of the Denoising Autoencoder process. The network successfully removes injected Gaussian noise, recovering the underlying signal structure [6].
6. The Generative Extension: Variational Autoencoders (VAE)
The standard autoencoder is a powerful tool for compression and feature extraction, but it harbors a critical limitation: it is not a generative model. Because the standard autoencoder is trained deterministically to minimize reconstruction error, its latent space is highly irregular and discontinuous. If you sample an arbitrary point from the latent space of an MLP or CNN autoencoder, the decoder will likely output meaningless noise.
To transition from a reconstructive model to a true generative model, we must enforce a continuous, densely packed probabilistic structure on the latent space. This is the foundational breakthrough of the Variational Autoencoder (VAE).
6.1. From Deterministic Encoding to Probabilistic Inference
In a classical autoencoder, the encoder maps an input to a single, discrete latent vector . In a VAE, the encoder maps the input to a probability distribution over the latent space.
Specifically, the encoder outputs the parameters of a multivariate Gaussian distribution: a mean vector and a variance vector .
During the forward pass, the latent representation is stochastically sampled from this distribution:
This probabilistic mapping ensures that similar inputs are encoded into overlapping topological regions, creating a smooth, continuous manifold where every local point corresponds to a valid, sensible reconstruction.
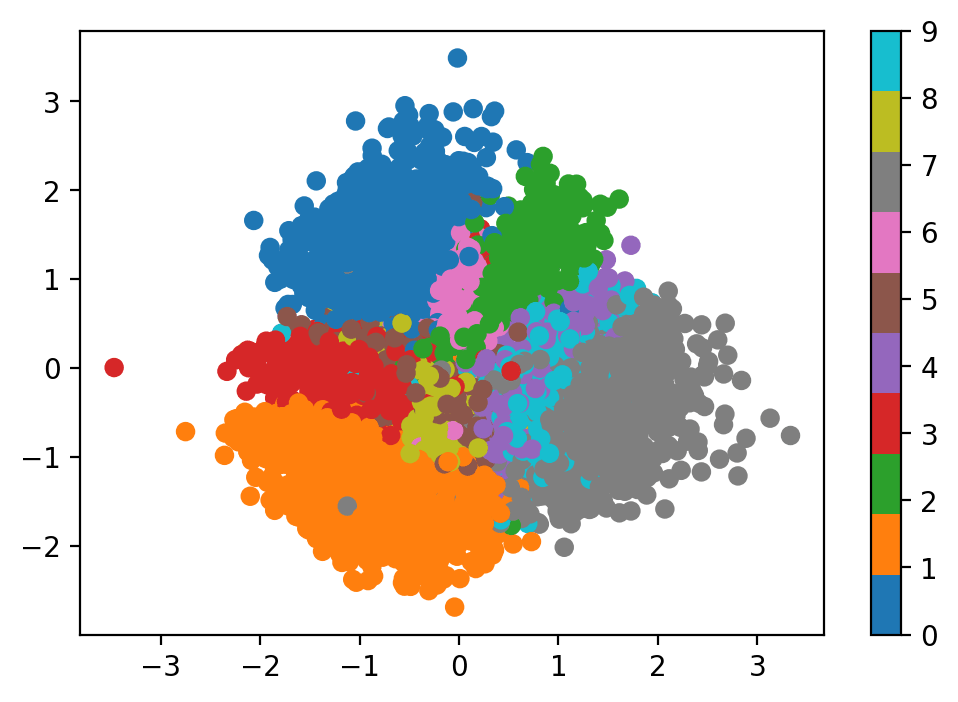
Figure 10 – Comparison of latent spaces. The standard autoencoder creates isolated points, while the VAE creates overlapping Gaussian spheres, ensuring a continuous generative manifold [7].
6.2. The Reparameterization Trick
A fundamental engineering challenge arises when introducing stochastic sampling into a neural network: you cannot backpropagate gradients through a random sampling operation. The sampling step blocks the deterministic chain rule required to update the encoder’s weights .
The reparameterization trick elegantly resolves this by mathematically decoupling the randomness from the learned parameters. Instead of sampling directly from the parameterized distribution, we sample a noise variable from a standard unit Gaussian prior, , and deterministically scale and shift it:
By routing the stochasticity into the independent auxiliary variable , the operations acting on and become standard differentiable nodes in the computational graph.
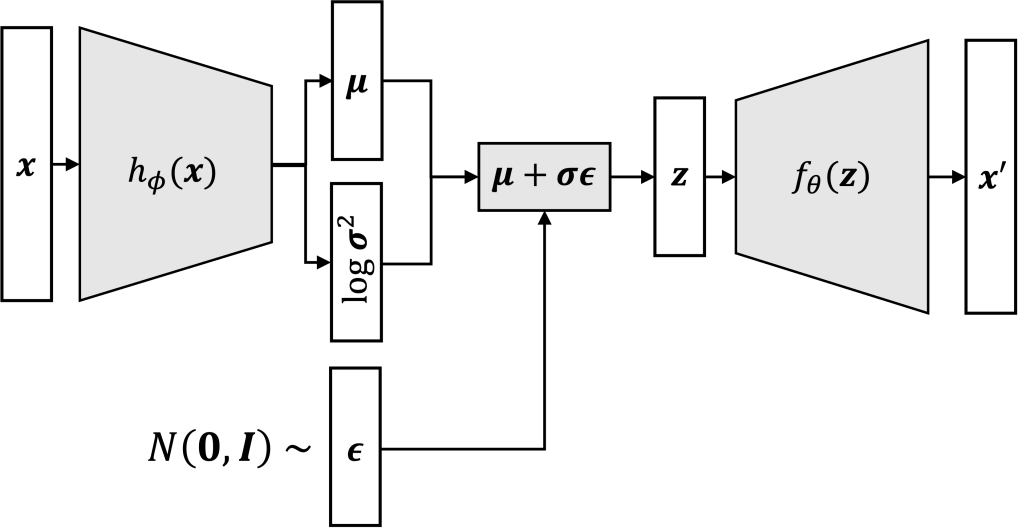
Figure 11 – The Reparameterization Trick. A computational graph showing how the stochastic node is sidestepped to allow uninterrupted gradient flow back to the encoder [2].
6.3. The Evidence Lower Bound (ELBO)
Training a VAE requires optimizing a dual-objective loss function. We want to maximize the likelihood of the data while ensuring the learned latent distributions closely resemble a chosen prior (typically a standard normal distribution). We achieve this by maximizing the Evidence Lower Bound (ELBO), which translates to minimizing the following loss function:
This equation consists of two opposing forces:
- The Reconstruction Loss (first term): Measures how well the decoder reconstructs the input from the sampled latent vector. This is typically implemented as Mean Squared Error (MSE) or Binary Cross-Entropy (BCE).
- The Kullback-Leibler (KL) Divergence (second term): Acts as a powerful regularizer. It measures the statistical distance between the encoder’s predicted distribution and the standard normal prior . It mathematically forces the latent distributions to pack closely around the origin, preventing the network from “cheating” by placing distributions infinitely far apart to avoid overlap.
For a multivariate Gaussian with diagonal covariance, the KL divergence term has a closed-form analytical solution:
6.4. PyTorch Implementation
In practice, for numerical stability, the encoder is designed to output the log-variance () rather than the variance directly.
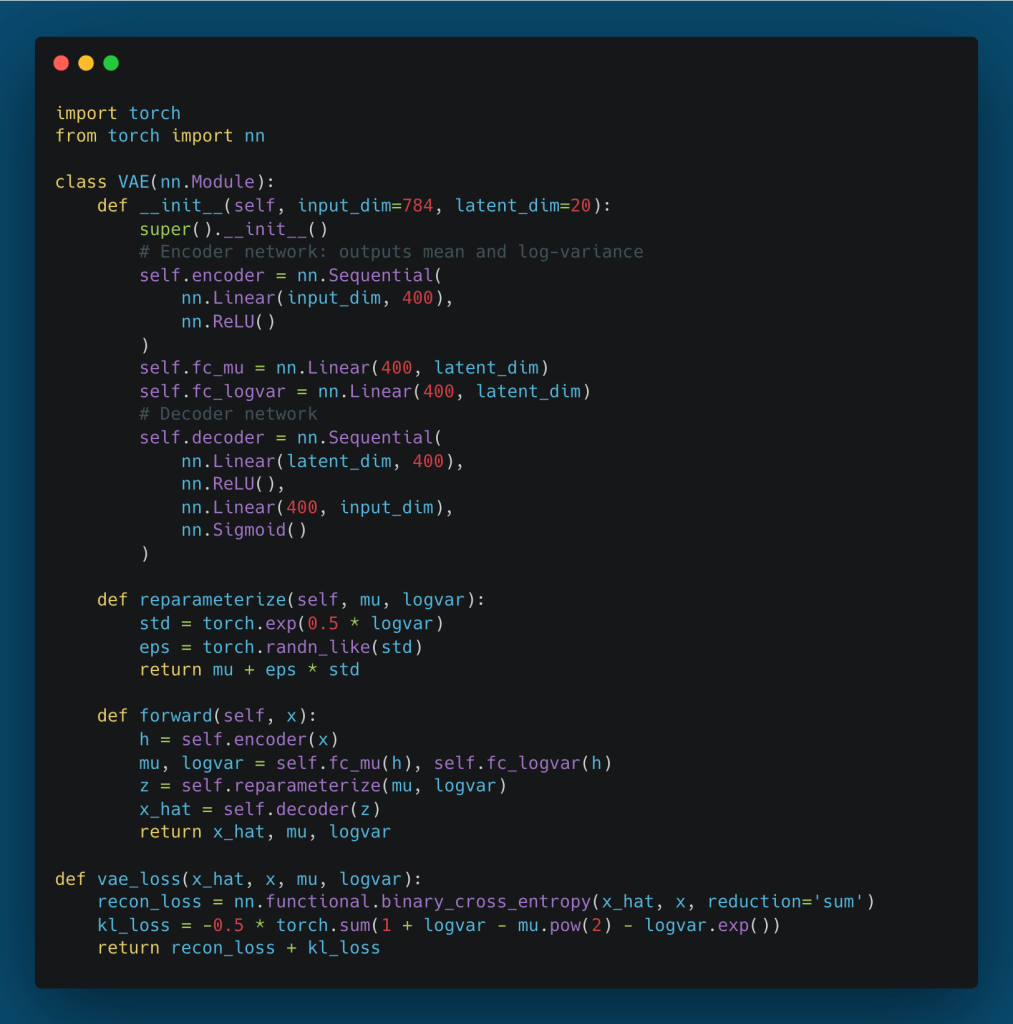
6.5. Generative Sampling and Latent Space Interpolation
Once the VAE is trained, the encoder is completely discarded for generation tasks. To synthesize entirely novel data, we simply sample a vector from the prior and pass it through the decoder.
Furthermore, because the KL divergence forces the space to be dense and continuous, we can perform latent space interpolation. By taking the latent vectors of two distinct real images ( and ) and calculating the linear sequence between them (), the decoder will generate a sequence of images that smoothly morphs from the first image to the second, representing structurally valid, intermediate semantic concepts.
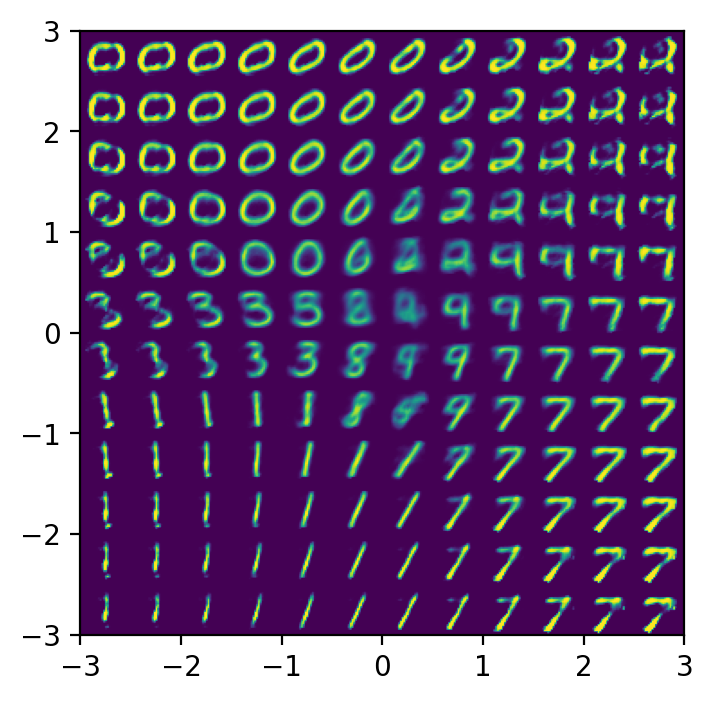
Figure 12 – Latent interpolation between MNIST digits, demonstrating how the model learns smooth semantic transitions (e.g., a “3” morphing cleanly into an “8”) rather than abrupt, noisy pixel shifts.
6.6. Legacy in Modern Generative AI
The Variational Autoencoder was a paradigm shift. Its probabilistic formulation of latent spaces served as the conceptual and architectural foundation for the current era of generative AI:
- -VAEs: Introduced a scaling factor to the KL divergence term, allowing researchers to force the network to learn highly disentangled representations (e.g., separating object color from object orientation into distinct latent dimensions).
- VQ-VAEs (Vector Quantized VAEs): Replaced the continuous Gaussian latent space with a discrete codebook. This solved the “blurriness” issue often associated with standard VAEs and became the foundational architecture for generating high-fidelity audio and images.
- Latent Diffusion Models: Systems like Stable Diffusion rely heavily on VAEs. Instead of running the expensive diffusion denoising process in raw, high-resolution pixel space, these models compress the image using a VAE encoder, perform diffusion strictly within the low-dimensional latent space, and then decode the result back to high resolution.
7. Conclusion
Autoencoders represent a masterclass in the power of architectural constraints. By simply forcing a neural network to compress and reconstruct its own input, we transition from relying on expensive, human-annotated labels to unlocking the intrinsic, self-supervised structure of the data itself.
Throughout this post, we have traced the evolution of this architecture:
- We began with the mathematical foundations of the encoder-decoder mapping and the probabilistic assumptions underlying standard reconstruction losses.
- We explored the MLP Autoencoder, understanding its utility for structured data but acknowledging its severe limitations regarding spatial locality and parameter efficiency.
- We solved those spatial limitations with the CNN Autoencoder, leveraging the inductive biases of convolutional filters to achieve high-fidelity image compression and feature extraction.
- We examined the immense practical value of these deterministic networks, particularly in unsupervised anomaly detection, where reconstruction error serves as a reliable boundary for normality across industrial, cybersecurity, and medical domains.
- Finally, we broke the deterministic barrier with the Variational Autoencoder (VAE). By introducing probabilistic inference, the reparameterization trick, and the ELBO objective, we transformed a simple reconstructive tool into a continuous, interpolatable generative model—laying the conceptual groundwork for the modern era of Generative AI.
Whether you are building a predictive maintenance pipeline to detect manufacturing anomalies, or studying the latent diffusion models that power today’s state-of-the-art image synthesis, the autoencoder remains an indispensable architectural pillar in the deep learning repertoire.
Hands-On Exploration: Interactive Autoencoder Framework
If you want to move beyond the theory and experiment with these architectures firsthand, I have built a modular, Interactive Autoencoder Framework available on my GitHub:
https://github.com/turhancan97/simple-autoencoder-demo
This repository provides a complete, YAML-configurable PyTorch pipeline to train and visualize MLP, CNN, and VAE models on datasets like MNIST. Its standout feature is the real-time demo.py application, which generates a visual 2D mapping of the trained bottleneck. By simply clicking and dragging your mouse across the latent space clusters, you can watch the decoder continuously generate and morph reconstructions in real-time. It is an excellent practical tool for observing the structural differences between the deterministic latent space of a standard MLP and the smooth, continuous generative manifold of a VAE.
Reference
- Dense in. Stack Overflow. Stack Overflow. Published 2019. Accessed October 30, 2025. https://stackoverflow.com/questions/55233114/how-to-create-autoencoder-using-dropout-in-dense-layers-using-keras
- Matthew Bernstein. Matthew N. Bernstein. Published March 14, 2023. Accessed October 30, 2025. https://mbernste.github.io/posts/vae/
- rvislaywade. Visualizing MNIST using a Variational Autoencoder. Kaggle.com. Published March 8, 2018. Accessed October 30, 2025. https://www.kaggle.com/code/rvislaywade/visualizing-mnist-using-a-variational-autoencoder
- Deep Discriminative Latent Space for Clustering. ResearchGate. Published online 2018. doi:https://doi.org/10.48550//arXiv.1805.10795
- AutoEncoder Convolutional Neural Network for Pneumonia Detection. (2024). ResearchGate. https://doi.org/10.48550//arXiv.2409.02142
- Rosebrock, A. (2020, February 24). Denoising autoencoders with Keras, TensorFlow, and Deep Learning – PyImageSearch. PyImageSearch. https://pyimagesearch.com/2020/02/24/denoising-autoencoders-with-keras-tensorflow-and-deep-learning/
- Van, A. (2020, May 14). Alexander Van de Kleut. Alexander van de Kleut. https://avandekleut.github.io/vae/
